Over time, the software we write continues to increase its sophistication. We are solving more and more advanced problems, expressing the solution as a specific sequence of ones and zeroes stored on the memory of a Turing-complete machine. These programs are steadily growing larger in size (today’s executables are typically on the order of a few megabytes, which is a few million 8-bit numbers), and require faster or more sophisticated (i.e. multicore) hardware to execute in reasonable time. But the human mind is not getting more advanced over time, at least not nearly at the same rate. We are as mentally advanced today as we were in the 1950s, but our computer programs are several orders of magnitude more advanced and complex. How can the human software developers who produce this code possibly keep up their understanding with something that is so rapidly increasing in complexity?
The answer is by abstraction. Today’s programmers do not hand-craft the millions of bytes of machine code instructions that ultimately form cutting edge software. Nor could they ever read the code in that format and hope to comprehend what it does, much less how it does it. Attempting to read and follow a modern software program in its compiled machine-language format is a clear demonstration of how vastly more complex computer software has become since the days when computer programs were hand-written machine code. Instead, programmers use high-level programming languages to write code. These languages contain much more abstract concepts than “add”, “move”, “jump” or the other concepts that machine instructions represent.
Properly understand, even machine code itself is an abstraction. Each machine instruction represents an abstract operation done to the state of the machine. We can take this abstraction away and watch the operation of a machine while executing a program, from the perspective of its electronic state. We can record the time at which different gates are switched to produce different sub-circuits. But even this is an abstraction. We can go below the level of switching gates and hook voltmeters to the circuits to produce a graph of voltage over time. While trying to understand what a computer program does by reading its machine code is hopeless, trying to understand what it does by recording the physical state of a machine running it is far more hopeless. It would be hopeless even to understand hand-written machine code from the 50s in this way (and doing so would proceed by first trying to rediscover the machine code). Even the very low-level (but very high-level, from the perspective of the electronic hardware that implements our Turing machines) abstraction of a central processor and a sequence of instructions to process aids massively in our ability to comprehend and compose software. Not even a trivial computer program could be feasibly designed by specifying the voltage on the terminals of circuits as a function of time.
But even when looking at modern programs on the higher level of their source code they are still, as a whole, intractable to human comprehension. It is not uncommon for a modern computer program to contain millions of lines of source code. How could a human possibly be able to understand something with millions of interworking parts?
The answer, again, is by abstraction. A “line” of source code is the lowest level of abstraction in a program’s source code. These lines are grouped together into functions. Functions are grouped together into classes. Classes are grouped together into modules. Modules are grouped together into subsystems. Subsystems are grouped together into libraries. Libraries are grouped together into applications. We can understand and follow something that ultimately takes millions of lines of code to express because we do not digest it in the form of raw lines. We understand the application as a composition of a handful of libraries. We do not attempt to understand how the libraries do what they do, as we try to understand the applications that use them. We only understand the libraries by what they do, and from that, we understand the application in terms of how it uses those libraries to implement its own behaviors. In a well-designed software application, the application-level code is not millions of lines of code. It is thousands, or even merely hundreds, of lines of code. This is what makes it tractable to the human mind.
But each of those lines is now far removed from what a computer can understand. A line of code calling a high-level library ultimately gets compiled down to what could be thousands of machine code instructions. By identifying a boundary between what and how, and equivalently why and what, we are able to take what is otherwise a massive and impenetrable problem, and factor it into individually digestible pieces. We do not simply divide the problem into parts by size. We cannot understand a compiled binary of millions of machine instructions by taking the first thousand and looking at them in isolation, then the next thousand, and so on. The division is conceptual and builds up a hierarchy of higher and higher-level concepts, linked together by a why-how relationship. The result is a series of layers, like the floors of a building. We call these abstraction layers.

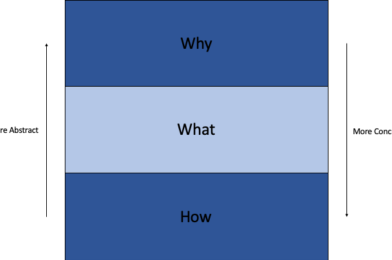
An abstraction layer is a “why”, “what” or “how” depending on from what perspective we are looking at it. When considering a particular abstraction layer, it becomes the subject of our consideration: the “what”. The layer immediately above it is, from this perspective, the “why”. This abstraction layer exists because the abstraction layer above it needs it. The layer immediately below it is, from this perspective, the “how”. It is what the current abstraction layer uses as its implementation details. If we then focus on the next layer down, it becomes the “what”, the previous layer becomes “why”, and the next layer down becomes “how”.
Abstraction layers are represented in different ways with different types of programming languages. In object-oriented languages, an abstraction layer is identified by a class, which has two parts: an interface and an implementation. When focusing on an interface, an implementation of that interface is the how. When focusing on the implementation, the interface is the why. Classes then link to each other through composition. The implementation of a class contains fields, which are references to other interfaces. A class’s implementation calls methods on its members, and on the parameters of its own methods. So then these other interfaces are the how of an implementation. When interface A is implemented by AImp, and AImp is composed of interfaces B and C, then A, AImp, and the set containing B and C each form abstraction layers, in order of most abstract to least abstract. AImp is the “how” of “A”, while A is the “why” of AImp. B and C are the “how” of AImp, while AImp is the (or a) “why” of B and C. Somewhere there will be a BImp and CImp, which continues the sequence of abstraction layers.
In functional languages, function declarations and function bodies perform the analogous roles to interfaces and implementations. A function body is the “how” of a function declaration, and the function declaration is the “why” of a function body. Meanwhile, a function body contains a sequence of calls to other function declarations (note that a call to a function is a reference to a function declaration, not to a function body). When function declaration A has a function body ABody, and ABody calls function declarations B and C, then A, ABody, and the set containing B and C form the analogous abstraction layers to A, AImp and {B, C} in the object-oriented example above.
Programmers navigate a computer program by starting at one implementation, and if needed, clicking on a line of code and selecting “go to definition”, which takes them to another implementation, with other lines of code that can also be followed to their definition. This is a navigation of abstraction layers, and demonstrates how they link together repeatedly.
This structure of different layers being linked together is fractal. On one level, a block of code is formed as multiple lines that call other blocks of code. Those blocks are similarly formed as multiple lines to yet other blocks of code. Thus the structure of code exhibits self-similarity at different scales.
Note that I said a well-designed application will contain a few hundred or thousand lines of code, in the form of calls to highly abstract library functions. But a poorly designed application may not organize itself into libraries at all, or do so in a poor fashion that prevents one from truly forgetting about what is under the hood of a single line of code. Lacking or improper abstractions forces one to digest a larger amount of information in a single “bite” in order to comprehend what the program does. This makes the program more difficult to understand, because a larger chunk of its inherent complexity must be considered all at once. Any small part of that chunk’s complexity requires dealing with all the rest of that chunk’s complexity. While no human programmer could possibly understand the machine-code version of a modern software program, it is commonplace for the source code of a modern application to stretch the ability of human comprehension to its limits. This takes the form of poorly designed computer code that is missing proper, well-formed abstractions that truly divide the problem into small, and truly distinct, bitesize pieces.
This leads us to the following principle of good software design, that serves as the foundation for all other software design principles:
The complexity in understanding computer code primarily varies proportionally with the distance between its abstraction layers
Each part of a computer program, however abstract, is implemented with less abstract, more concrete code, until one reaches the level of machine code. By “distance between abstraction layers”, we mean how much less abstract a certain layer’s implementation is than its interface. If the gap is very large, a class’s methods will inevitably be very long, difficult to follow and difficult to understand. The gaps can be closed by introducing dividing abstractions: an abstraction layer placed above the low-level implementation details as they currently are, but below the high-level interface being implemented. The implementation of those intermediate abstractions is simpler because the abstraction is closer to the implementation details. Meanwhile, the implementation of the higher abstraction in terms of this intermediate abstraction is simpler than the original implementation, for the same reason.
From this it is clear that more and more advanced computer programs, with human designers, are only made possible by building upon the less advanced programs we have already built. This is quite literally how computers have advanced. The first computer programs had to be hand-written in machine code. But then programmers hand-wrote the machine code for an assembler, which enabled them to then write programs in assembly. With an assembler, they could then write a self-hosting assembler: an assembler whose own source code is not only written in its own assembly language, but that can be successfully assembled by itself. Then they wrote a BASIC compiler in assembly, which then enabled writing a self-hosting BASIC compiler. Then they wrote a C compiler in BASIC, and then a self-hosting C compiler. Then they wrote a C++ or Smalltalk compiler in C, and then self-hosting C++/Smalltalk compilers. Today, we have high-level programming languages like Java, which were, and often still are, implemented with lower level languages. Each step is a tool, that becomes the means to constructing a more sophisticated tool, which in turn becomes the means to construct an even more sophisticated tool, and so on. The tools, which are computer programs themselves, becomes more and more sophisticated, which enables the creation of not only sophisticated programs in general, but more sophisticated tools in particular.
This process is not peculiar to the development and advancement of computer software. It is rather the general means by which humans have produced all the extremely advanced and sophisticated things they have produced. A man uses his bare hands to fashion tools from stone, which he then uses to fashion a forge, which he then uses to fashion metal tools, which he then uses to fashion mechanical devices, which he then uses to fashion engines, which he then uses to fashion factories, which he then uses to fashion electronics, which he then uses to fashion all the advanced technology that surrounds us today. We start by hand-crafting consumer goods. Then we hand-craft tools that we use to craft consumer goods. Then we hand-craft tools to make other tools. Then we craft tools to make the tools we use to make other tools. And so on.
Economists call this process the elongation of the production structure: a process by which the production goes through increasingly more steps. Instead of directing building the thing we want, first we build a thing that builds the thing we want. Even more indirectly, we build the thing that builds the thing that builds the thing we want. This continues until, in a modern industrial and electronic economy, the actual end-to-end process of manufacturing a good from nature-given resources, when taking into account the production of all the tools used in its production, takes hundreds or thousands of steps, involving resources acquired from and shipped around all parts of the world, and occurring over many years or even decades.
A modern economy is so complex that it can never be understood all at once by any of the humans whose actions constitute that economy. Nor does it need to be understood all at once by its operators in order to function. Instead parts of it are understood in isolation, and in how they fit into the parts immediately adjacent. No people organize or coordinate the economy as a whole. A person focuses on one small part, which is possible because the incredibly complex process of modern production has been factored out into conceptually well-formed parts (repeatedly, in a fractal way) that remain well-defined and identifiable in isolation. If anyone attempted to understand a production process by reading a graph of positions of all the factors involved, as a function of time, they would be hopelessly lost.
The factors of production (tools and machines) of modern industry are implementations of abstractions. We are able to define the requirement of a tool or machine as a derived requirement of producing something else (another tool/machine or a consumer good/service), because we are able to identify a high-level concept in the process of producing something. If we defined production of a good in terms of the sequence of movements of physical objects over time that takes place in the process as it is done now, we would have no way of moving to a different sequence of movements of different objects and meaningfully say that the same production process has occurred (or even that the same thing has been produced). By identifying the “what” as distinct from the “how”, the “how” becomes interchangeable. This is the only way to correctly express a requirement. The definition of producing a sandwich does not include details like taking a bladed piece of metal and moving it in a zig-zag pattern through a piece of bread. Such details do not define a sandwich. What defines a sandwich is sliced bread. That definition relies on our ability to identify a high-level abstraction called “sliced”, which can be independently defined and verified. It is not just a matter of allowing variation in the implementation details of making a sandwich. It is about correctness. It is simply wrong to define a sandwich by how the bread was sliced.
This is what we do in computer software when we abstract it. We correctly define the requirement, which defines the what and not the how. At the same time, the requirement itself is the “how” of some other, higher-level and more abstract requirement. For example, the requirement to present an upgrade screen to a user is the “how” of a more abstract requirement to enable users to upgrade their accounts, which itself is the “how” of a still more abstract requirement to maximize profits. On each level, it is not simply inconvenient or inflexible to put the “how” into the definition of a requirement. It is simply wrong. It does not correctly express what the requirement actually is, in the sense of specifying what conditions need to be met in order to say the requirement has been satisfied.
This is so deeply entwined into the structure of human thought, it is not really possible for us to imagine anything without it. What we call “abstractions” here, are what in language are called “words”. Every word in a language is an abstraction. A word has a definition, which is another collection of words. A word a high-level abstraction, with the words in its definition being lower-level abstractions. The process of the human mind taking in data and structuring it into a form that is comprehensible to logical thought, is a process of abstraction. To try to think about something without abstractions at all is to try to think without using language (even one you invented yourself), which is an oxymoron.
Recognizing the fundamental role of abstracting, and more specifically properly abstracting, while designing computer software, is none other than recognizing that abstracting underlies the very process of logical structuring that the human mind does to make reality understandable. It has perhaps required more explicit emphasis in software than in other places (like manufacturing), because the virtual worlds we are creating in software are more malleable than the real one. It is less obvious that the higher-level concepts in our code must follow a logical structure, because we create them from scratch (in a sense), than the higher-level physical entities we construct in the real world. It is perhaps easier to see why a car needs to be built as a composition of an engine, a transmission, an axel, and so on, than it is to see why an application needs to be built as a composition of a user interface, bindings, models, use cases, services, stores and so on. After all, aren’t all of these things just “made up”? It’s all 1s and 0s in the end, right?
But these are all just mental constructs. That a car is composed of an engine, a transmission, an axel, and so on, is only apparent to the mind of a rational observer. It is not part of the physics of the car itself, which is, ultimately, just a distribution of mass and energy throughout space over time. These “parts” of a car as just as “made up” as the parts of a software application. They are both abstractions above the “raw” physical level of reality. As they belong to the same category, they are just as important. Trying to build software without abstractions (specifically proper abstractions) is as hopeless as building a car as a big jumbled pile of moving masses. Good design of computer software ultimately comes down to whether the problem being solved has been correctly understood and broken down, with all the lines between what/why and how/what have been drawn in the right place. Good design derives from identifying the proper abstractions, and expressing them as such in code.
If you find yourself straining to comprehend the codebase you are working on, it could be that the problem you are trying to solve is so irreducibly complex that it is almost impossible to grasp. But much more likely (especially if you are working on a GUI application), your codebase is poorly abstracted and needs to be conceptually organized. Good design all flows downhill from having the virtual world of a codebase composed of well-defined abstractions (the “well-defined” part is typically given names like “high cohesion” in design discussions, which really means the “thing” being considered has a concise and straightforward definition). The benefit you reap from discovering and using such abstractions is as great as the benefit to human society of creating their wealth with a series of tools and machines rather than by hand. It will be the difference between an impoverished software shop and an affluent one.